
Solving Coronary Risk: Time to Feed Machines Some Calcium (Score) Supplements

Coronary artery calcium (CAC) has emerged as a valuable imaging biomarker to provide direct evidence of coronary atherosclerosis, and gives valuable prognostic information.[1] In symptomatic patients, there is a positive correlation between increasing CAC and the presence of obstructive coronary artery disease (CAD).[2] On the other hand, symptomatic patients with zero CAC score have been shown to have a low risk of adverse cardiovascular events (0.8–1.4%).[3,4] Most risk calculators for estimating pre-test probability of obstructive CAD have been developed using statistical models in population-based studies with linearity assumption of risk factors for the presence of flow-limiting CAD. As a consequence, the pre-test probabilities of current risk calculators overestimate the actual prevalence of obstructive CAD.[5]Therefore, better models that integrate CAC scores into risk prediction are needed to improve diagnostic performance of the model.
Machine learning (ML) offers an alternative approach to standard statistical models for improving personalized predictions. To this end, Al’Aref and colleagues, in this issue of the European Heart Journal, present an ML model to predict the presence of obstructive CAD among stable chest pain patients using 25 clinical and demographic factors alone or in combination with CAC scores.[6] Ensemble learning was used to develop a supervised learning model to compare with traditional risk scoring models. They used CAD consortium clinical score and the updated Diamond–Forrester (UDF) score for the prediction of obstructive CAD. As the CAC score was added to the model, the diagnostic performance of the ML model and CAD consortium clinical score [area under the curve (AUC) 0.881 and 0.866, respectively] significantly improved. CAC was the most predictive variable in the risk factor + CAC ML model, followed by age and gender. Moreover, the sensitivity, specificity, positive predictive value, negative predictive value, and accuracy of the ML model improved considerably with CAC score addition to the model at a disease probability threshold of 15% (80.0, 81.5, 49.1, 94.8, and 81.3% for risk factors + CAC ML model). Despite having similar diagnostic performance for risk factor + CAC ML and CAD consortium + CAC models (0.88 vs. 0.866), the risk factor + CAC ML model performed better in younger individuals (<65 years of age) presenting with atypical symptoms (AUC 0.875 vs. 0.702, respectively).
The study by Al’Aref and colleagues exemplifies the eagerness in the scientific community to use ML to improve cardiovascular risk prediction algorithms.[7,8]Given that an ML algorithm outperforms traditional risk factor-based CVD prediction models, particularly in younger individuals, how can this be used clinically? Based upon these data, an ML model using risk factors and CAC may be helpful, especially among low to intermediate risk stable chest pain patients, to reclassify their risk. If the CAC score is zero, patients can probably be reclassified to low risk, and may not need further testing apart from risk factor modification. A positive CAC score may further reaffirm elevated risk and further need for cardiac testing to evaluate for obstructive CAD. A zero CAC score, however, may fail to capture non-calcified plaques, which are less stable and more likely to rupture.[9] The use of ML for these patients may augment the physician’s abilities to confirm the risk despite the CAC score being zero; reclassifying the patient as an elevated- or low-risk individual, and establishing the appropriate need for further testing during an index visit (Figure 1). Individuals with symptoms and a relatively high pre-test probability of disease would benefit directly by undergoing coronary anatomy evaluation despite a zero CAC score. The potential role of ML to further risk-stratify high-risk individuals would need to be addressed in future clinical trials.
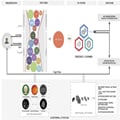
Figure 1.
Strategy for initial evaluation of patients presenting with stable chest pain. The upper panel identifies the steps and potential clinical application of the study by Al’Aref and colleagues. The lower section of the figure identifies potential features that could be used and the different machine learning models that could be studied in the future for improving the disease classification. BMI, body mass index; CAC, coronary artery calcium; Cr, creatinine; CVA, cerebrovascular accident; DM, diabetes mellitus; HTN, hypertension; HCL, hypercholesterolaemia; HDL, high-density lipoprotein; ML, machine learning; PVD, peripheral vascular disease.
A recent systematic review was unable to substantiate a claim that clinical prediction models based on ML lead to better AUCs than clinical prediction models based on simple statistical models such as logistic regression.[10] Why would one then still expect an ML-based model to perform better than existing statistical models? Given that one of the advantages of ML lies in better prediction from big and complex data that require multiple levels of abstraction, representation, and information retrieval, there are several clinical factors and methodological approaches worthy of future considerations (Figure 1). First, the absence of obstructive CAD does not necessarily mean that the prognosis is benign. Thus, a composite outcome of non-obstructive disease and future risk of a cardiac event would be worth evaluating. Secondly, a future algorithm would need to be trained on predicting the presence or absence of high-risk CAD (left main or three-vessel disease). Thirdly, the use of newer approaches such as deep neural networks to extract features directly from CAC images including location, distribution, and the density pattern of detectable calcified plaque could further improve the diagnostic yield. Fourthly, the abilities of deep learning models to estimate the Agatston score from any non-contrast chest computed tomography (CT), low-dose CT scans, or arterial calcifications in mammograms could reveal unprecedented screening opportunities. Finally, newer paradigms with abilities for deep learning algorithms to extract cardiac risk profiles from patients’ facial features,[11] retinal images,[12] or mobile sensor data that monitor physiological functions and bio-signals such as ECG[13] could help build new cohesive taxonomy of latent cardiac risk. While feeding such diverse and up to date sets of data for fine-tuning the ML prediction models, it will be imperative to prospectively validate the predictions in the real-world scenario. Furthermore, with the burgeoning use of deep generative models for imitating real-world images and data, novel ML techniques such as generalized adversarial networks could empower physicians to generate and visualize the evolution of coronary plaques, their composition, distributions, and underlying instabilities as the mechanistic basis of the future adverse coronary events. While studies such as that presented by Al’Aref and colleagues signal the great potential of ML techniques to speed and disrupt every foundational aspect of cardiac clinical research, it is imperative that we train a new generation of researchers who can embrace data science to bridge the gap between transparent ML systems and existing domain knowledge.